Amazon Forecast with Lambda Step Functions and CloudWatch Events rule
Posted By : Adarsh Singh | 09-Mar-2021
Below is the list on which Forecast is applicable:
- Estimating product demand
- Energy demand
- Workforce planning
- Computing cloud infrastructure usage
- Traffic demand
- Supply chain optimization
- Financial planning
It is a completely managed service, so we don't' need servers or ML models to build manually. What's excellent is there is no minimum fee or upfront commitment. You only pay for what you use. Just provide the systematic data you want to forecast and it's done. With-in time may include both time-varying data, like price, weather, and events, and categorical data, like color, genre, and maybe region. Once you provide the data, the service will automatically train and deploy the machine learning models based on the data and API.
Let's discuss the system architecture for Amazon Redshift for using Forecast to manage hardware and help customers spin up with Redshift clusters quickly.
Use case background:
Amazon Redshift is a petabyte- or even exabyte-scale data warehouse and fully managed service. An Amazon Redshift cluster can initiate one or more nodes. To building a cluster as fast as you can to provide the best customer experience, it maintains cache pools to contain a certain number of nodes with pre-installed database software, normally referred to as a warm pool.
Whenever Amazon Redshift get requests for a new cluster, it grabs the required number of nodes from the cache pools. it stores every request and each entry contains the following attributes:
- Location
- Timestamp
- NumberOfNodes
Also Read: A Brief Introduction To The Hidden Markov Model
The following table presents an example of data.

It is critical to quickly meet the demand while minimizing the running cost of the right number of nodes in the cache pool. Managing less capacity in the pool decreases the cluster delivery rate and it will affect the customer experience. And if we manage a lot of clusters, it will increase the cost. The forecast is used in Amazon Redshift to predict the demand for nodes at any given time.
Overall system architecture:
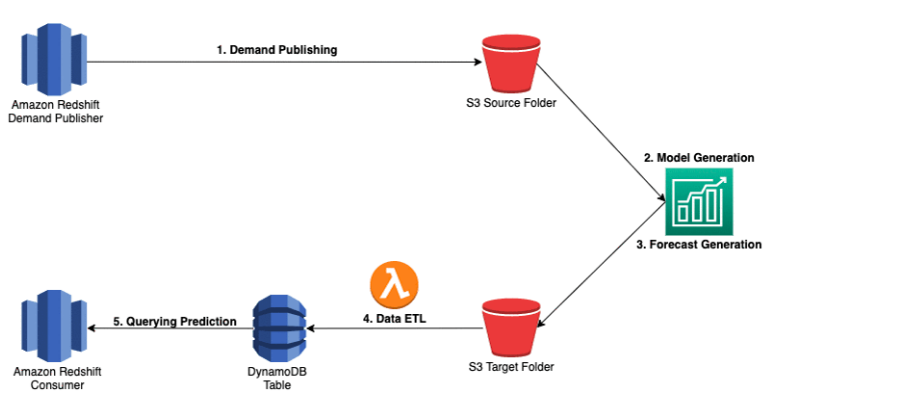
We can take an overview of the system architecture in the following diagram that Amazon Redshift has implemented for prediction node demand using Forecast.
1. Raised demand using AWS services like Lambda, Step Functions, and Amazon CloudWatch Events rule to periodically (run cycle at a pre-defined time) query the database and update the past some months required data into the source Amazon S3
2. Define the model using the services rule to call Forecast APIs to create and modify the model.
3. Define forecasts using services rule to periodically (hourly) call Forecast APIs and send the predictions into the defined S3 bucket.
4. Amazon DynamoDB table filled by using a Lambda function from the S3 bucket, whenever there is the latest file with predictions in the target S3 bucket or folder.
5. Query DynamoDB directly to determine future demand.
Images Source: https://d2908q01vomqb2.cloudfront.net/f1f836cb4ea6efb2a0b1b99f41ad8b103eff4b59/2020/02/19/forecast-workflow.gif
Hope you find this blog useful. If you have any queries related to the subject, please let us know in the comments section below. For any technical assistance, drop us a line at [email protected] or contact us here for SaaS App Development Services.


Cookies are important to the proper functioning of a site. To improve your experience, we use cookies to remember log-in details and provide secure log-in, collect statistics to optimize site functionality, and deliver content tailored to your interests. Click Agree and Proceed to accept cookies and go directly to the site or click on View Cookie Settings to see detailed descriptions of the types of cookies and choose whether to accept certain cookies while on the site.







{kind=link}
About Author
Adarsh Singh
Adarsh Singh is working as Front-End developer, having good knowledge of Angularjs, Javascript, Html, Less.