Tuning consistency with Apache Cassandra
Posted By : Shubham Singh | 29-Sep-2019
One of the challenges faced by distributed systems is how to keep the replicas consistent with each other. Maintaining consistency requires balancing availability and partitioning. Fortunately, Apache Cassandra lets us tune this balancing according to our needs. In this blog, we are going to see how we can tune consistency levels during reads and writes to achieve faster reads and writes.
Before digging more about consistency let me first discuss CAP Theorem.
CAP Theorem describes the tradeoffs in distributed systems, it states that any networked shared-data system can have at most two of three desirable properties:
-
consistency (C): All the nodes should have same data at the same time
-
high availability(A) : Every request should be addressed
-
tolerance to network partitions (P) : The system should continue to operate even in case of network partitions.
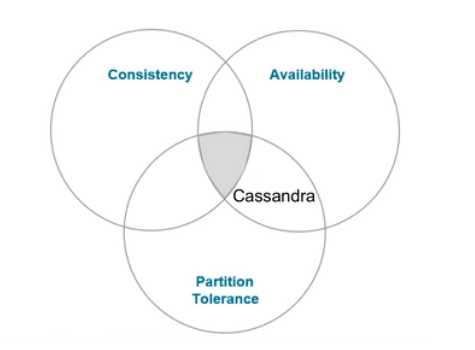
Consistency is very difficult to achieve in a distributed environment because we need all the replicas to be in sync with each within data centers and across data centers. As you can see in the diagram that Cassandra follows AP.
It optimizes Availability and Partition Tolerance itself but for consistency, it gives flexibility by letting us tune it based on how much consistency we need in our data.
Let’s get familiar with some terminologies which will be used:
– RF(Replication Factor) – Number of copies for data
– CL(Consistency Level) – Number of nodes required to acknowledge the read or write.
So, the real question now is how we can tune consistency?
Consistency Levels are a part of the writes. While writing data, we need to mention the consistency level with which we want to write and while reading data, we need to ask for a particular consistency level. This control has been given to the developer.
Let’s take the example of writing data.
For example, let’s say, RF=3, meaning data is to be copied to 3 nodes.
How do we make sure the data is written completely to all the nodes? Yes, you are right, we need an acknowledgment that the work is complete, this is exactly what CL provides.
-
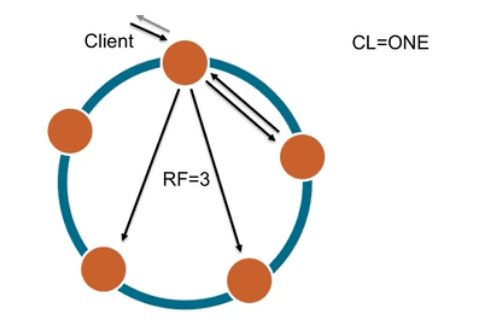
CL=ONE
– Only one node is required to acknowledge the read or write.
– If acknowledgment from any one node is received, that write is marked as done, but the data is still being written to the other two nodes asynchronously. It’s just that only one node’s acknowledgment is included in the response.
– This is the fast consistency level.
-
CL=QUORUM
–At least 51% of the nodes need to acknowledge write.
-Considering RF=3, we need 2 nodes out of 3 nodes to acknowledge the write, the third node will still get data asynchronously.
-QUORUM = (Replication Factor / 2) + 1

-
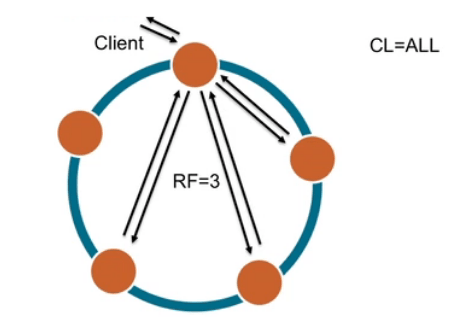
CL=ALL
–Meaning all the nodes need to acknowledge the write.
-This is not recommended until and unless you have a use case for it, as this will be equivalent to turning off the partition tolerance and availability in order to be consistent all the time.
So, as stated above, we can adjust the consistency according to the business needs. Let’s see what different options we have:
Strong consistency: The data which we just wrote, should be available when we read it stating there is no stale data.
But how can we achieve it??
-
WRITE CL=ALL, READ CL=ONE: Not at all recommended for production environments as it will make writes slow.
-
WRITE CL=QUORUM, READ CL=QUORUM: it will give high read and write speed without sacrificing availability.
Eventual consistency: The data we just have written will be available to all nodes eventually( as copying to other nodes is done in the background. This approach has low latency. Best useful for analytical data, time-series data, log data.
How can we maintain consistency across Multiple data centers:
LOCAL QUORUM: Only local replicas are considered in acknowledging the writes, data still gets written to the other data center. It provides strong consistency along with speed.
All the available consistency levels in Cassandra(weakest to strongest) are as follows:
-
ANY
-
ONE, TWO, THREE
-
QUORUM
-
LOCAL_ONE
-
LOCAL_QUORUM
-
EACH_QUORUM
-
ALL(not in for availability, all in for consistency)
For multiple data-centers, the best CL to be chosen are: ONE, QUORUM, LOCAL_ONE
Consistency plays a very important role. Consistency and replication are glued together. Consistency is all about how up-to-date all the replicas at any given moment, and consistency level determines the number of replicas that need to acknowledge the success of read or write operation.
Thanks


Cookies are important to the proper functioning of a site. To improve your experience, we use cookies to remember log-in details and provide secure log-in, collect statistics to optimize site functionality, and deliver content tailored to your interests. Click Agree and Proceed to accept cookies and go directly to the site or click on View Cookie Settings to see detailed descriptions of the types of cookies and choose whether to accept certain cookies while on the site.







About Author
Shubham Singh
Shubham working as Java Developer. He is always ready to face new problem and keen to explore new technologies. He has knowledge of Java,HTML,CSS, JavaScript. He likes to work with full dedication and coordination.