Installing Hadoop 3.2.1 On Ubuntu 16.04
Posted By : Anirudh Bhardwaj | 21-Jul-2020

Hello! In this blog, I will show you how we can install Hadoop version 3.2.1 in distributed mode on Ubuntu 16.04. I have installed VirtualBox to create three virtual machines for the nodes on my machine.
Step 1: Virtual machines and configuration changes
I have assigned the permanent IP address to my virtual machines by changing the configuration of my TP-Link router. The IP of machines are mentioned below 192.168.0.10
192.168.0.11
192.168.0.12
I have done some configuration changes on each virtual machines as mentioned below.
Machine 1: I have installed NameNode on this machine IP: 192.168.0.10
hostname: server1-cluster1
I have edited the /etc/hosts file $ sudo vim /etc/hosts and entered the following information in the host file 192.168.0.10 server1.bigdata.com
192.168.0.11 server2.bigdata.com server2-cluster1 192.168.0.12 server3.bigdata.com server3-cluster1
Now this machine knows machines 192.168.0.11 as “server2.bigdata.com” or “server2-cluster1” and 192.168.0.12 as “server3.bigdata.com” or “:qserver3-cluster1”
After editing the /etc/hosts file look like as below.
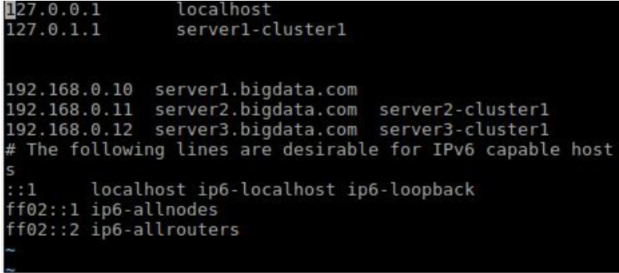
Similarly, I have added /etc/hosts file for the other two machines.
Machine 2: I have installed Secondary NameNode on this machine IP: 192.168.0.11
host name: server2-cluster1
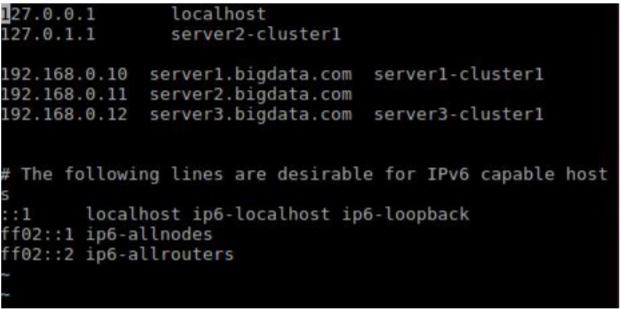
Machine 3: I have installed NameNode on this machine IP: 192.168.0.12
host name: server3-cluster1
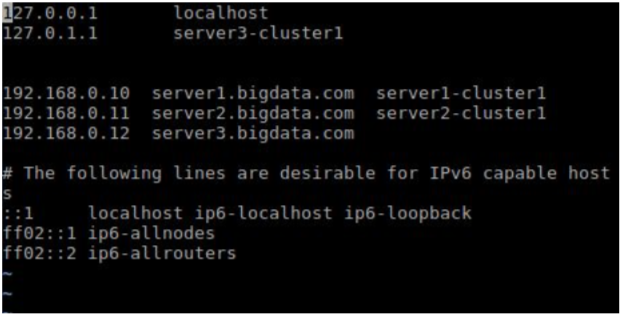
Step 2: Java Installation ( On all machines )
Install the required Java version on each of the virtual machines as mentioned on the link
https://cwiki.apache.org/confluence/display/HADOOP2/HadoopJavaVersions
I have installed OpenJdk 8 on the virtual machines.
Java installation command
$sudo apt-get install openjdk-8-jdk
Java command to check the version
$javac -version
Step 3: ssh installation ( On all machines )
ssh must be installed and sshd must be running to use the Hadoop scripts that manage remote Hadoop daemons if the optional start and stop scripts are to be used. Additionally, it is recommended that pdsh also be installed for better ssh resource management.
The command to install ssh $sudo apt install ssh
Command to install pdsh $sudo apt install pdsh
Step 4: Create new user and group on Ubuntu ( On all machines )
I have created a group with the name “big data” and user with the name “Hadoop user”.
Command to create the group (group name is bigdata) $sudo addgroup bigdata
Command to create a new user and add to the group ( Added hadoopuser to the group bigdata )
$sudo adduser --ingroup bigdata hadoopuser
Step 5: Configuring ‘sudo’ permission for the new user - “hadoopuser” ( On all machines )
The command to open the sudoers file $ sudo visudo
Since by default, Ubuntu text editor is nano we will need to use CTRL + O to edit. Add the below permissions to sudoers.
hadoopuser ALL=(ALL) ALL
Use CTRL + x keyboard shortcut to exit out. Enter Y to save the file
Step 6: Switch user to “hadoopuser”
Command to switch user $su hadoopuser
Step 7: Configuring Key based login on Master Node ( server1.bigdata.com ) so that it can communicate with slaves through ssh without password
Command to generating a new SSH public and private key pair on your master node $ ssh-keygen -t rsa -P ""
Below command will add the public key to the authorized_keys $ cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
Command to making sure that 'hostname' is added to the list of known hosts so that a script execution doesn't get interrupted by a question about trusting computer's authenticity. $ ssh hostname
ssh-copy-id is a small script which copy the ssh public-key to a remote host; appending it to your remote authorized_keys.
$ ssh-copy-id -i $HOME/.ssh/id_rsa.pub [email protected]
$ ssh-copy-id -i $HOME/.ssh/id_rsa.pub [email protected]
ssh is a program for logging into a remote machine and for executing commands on a remote machine. Check remote login works with password or not.
$ ssh server2.bigdata.com
Exit from remote login with ‘exit’ command $ exit
Step 8: Creating Hadoop installation directory and configuring permission ( On all machines )
I have created the directory name local at path /opt/ . Please create /opt directory first in case it doesn’t exist
Command to create ‘local’ directory at path ‘/opt/local/’ sudo mkdir /opt/local
Changing the ownership and permissions of the directory /opt/local
$ sudo chown -R hadoopuser:bigdata /opt/local/ $ sudo chmod -R 755 /opt/local
Step 9: Configuring hadoop tmp directory ( On all machines )
Hadoop tmp directory is used as base for the temporary directories locally
Command to create ‘tmp’ directory $ sudo mkdir /app/hadoop
$ sudo mkdir /app/hadoop/tmp
Command to change ownership to hadoopuser and group ownership to bigdata $ sudo chown -R hadoopuser:bigdata /app/hadoop
Command to change the read and write permission to 755 $ sudo chmod -R 755 /app/hadoop
Perform Step 10 to Step 18 on the Hadoop Master Node ( server1.bigdata.com ) Step 10: Downloading Hadoop
Command to change directory to hadoop installation directory in our case it is /opt/local $cd /opt/local
I have downloaded hadoop 3.2.1 using wget command
$wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
Command to extract hadoop $tar -xvzf hadoop-3.2.1.tar.gz
Command to rename extracted directory hadoop-3.2.1 $mv hadoop-3.2.1 hadoop
Step 11: Configuring hadoop environment variables
Edit $HOME/.bashrc file by adding the java and hadoop path.
sudo gedit $HOME/.bashrc
Add the following lines to set the Java and Hadoop environment variable export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/local/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=/opt/local/hadoop/lib/native" export PDSH_RCMD_TYPE=ssh
Reload your changed $HOME/.bashrc settings
$source $HOME/.bashrc
Step 12: Setting JAVA_HOME in the hadoop-env.sh file
Change the directory to /opt/local/hadoop/etc/hadoop $cd $HADOOP_HOME/etc/hadoop
Edit hadoop-env.sh file. $sudo vim hadoop-env.sh
Add the below lines to hadoop-env.sh file. Save and Close. export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
Step 13. Edit the core-site.xml file as below:
<configuration>
<property>
<name>fs.default.name</name> <value>hdfs://server1.bigdata.com:9000</value> </property>
<property> <name>dfs.permissions</name> <value>false</value> </property>
<property>
<name>hadoop.tmp.dir</name> <value>/app/hadoop/tmp</value>
<description>A base for other temporary directories.</description> </property>
</configuration>
Step 14: Edit the hdfs-site.xml file as below <configuration>
<property>
<name>dfs.name.dir</name> <value>/app/hadoop/tmp/namenode</value> </property>
<property> <name>dfs.data.dir</name>
<value>/app/hadoop/tmp/datanode</value> </property>
<property> <name>dfs.replication</name> <value>2</value>
</property>
<property> <name>dfs.permissions</name> <value>false</value> </property>
<property> <name>dfs.datanode.use.datanode.hostname</name> <value>false</value>
</property>
<property> <name>dfs.namenode.datanode.registration.ip-hostname-check</name> <value>false</value>
</property>
<property>
<name>dfs.namenode.http-address</name> <value>server1.bigdata.com:50070</value>
<description>Your NameNode hostname for http access.</description> </property>
<property>
<name>dfs.namenode.secondary.http-address</name> <value>server2.bigdata.com:50090</value>
<description>Your Secondary NameNode hostname for http access.</description> </property>
</configuration>
Step 15: Edit the yarn-site.xml as below
<configuration>
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value>
<description>Long running service which executes on Node Manager(s) and provides MapReduce Sort and Shuffle functionality.</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>Enable log aggregation so application logs are moved onto hdfs and are viewable via web ui after the application completed. The default location on hdfs is '/log' and can be changed via yarn.nodemanager.remote-app-log-dir property</description> </property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name> <value>2560</value>
<description>Amount of physical memory, in MB, that can be allocated for
containers.</description> </property>
<property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>256</value>
</property>
<property>
<description>Minimum increment setting - set to same as min-allocation</description> <name>yarn.scheduler.increment-allocation-mb</name>
<value>256</value>
</property>
<property>
<description>Max available cores data node.</description> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>2</value>
</property>
<property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>2048</value>
<final>false</final>
</property>
<property> <name>yarn.resourcemanager.hostname</name> <value>server1.bigdata.com</value>
</property>
<property> <name>yarn.resourcemanager.scheduler.address</name> <value>server1.bigdata.com:8030</value>
</property>
<property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>server1.bigdata.com:8031</value>
</property>
<property> <name>yarn.resourcemanager.address</name> <value>server1.bigdata.com:8032</value> </property>
<property> <name>yarn.resourcemanager.admin.address</name> <value>server1.bigdata.com:8033</value>
</property>
<property> <name>yarn.resourcemanager.webapp.address</name> <value>server1.bigdata.com:8088</value>
</property>
</configuration>
Step 16: Edit the mapred-site.xml as below <configuration>
<property> <name>mapred.job.tracker</name> <value>server1.bigdata.com:9001</value> </property>
<property> <name>mapreduce.framework.name</name> <value>yarn</value>
</property>
<property> <name>mapreduce.map.memory.mb</name>
<value>256</value> </property>
<!-- Default 1024. Recommend setting to 4096. Should not be higher than YARN max allocation -->
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>256</value> </property>
<property>
<description>Application master allocation</description> <name>yarn.app.mapreduce.am.resource.mb</name> <value>256</value>
</property>
<!-- Recommend heapsizes to be 75% of mapreduce.map/reduce.memory.mb --> <property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx204m</value> </property>
<property> <name>mapreduce.reduce.java.opts</name> <value>-Xmx204m</value>
</property>
<property>
<description>Application Master JVM opts</description> <name>yarn.app.mapreduce.am.command-opts</name> <value>-Xmx204m</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/opt/local/hadoop</value>
</property> <property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/local/hadoop</value> </property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/local/hadoop</value> </property>
</configuration>
Step 17: Edit worker and add the following line to the worker
server2.bigdata.com server3.bigdata.com server1.bigdata.com
Step 18: Secure copy or SCP is a means of securely transferring computer files between a local host and a remote host or between two remote hosts
Here, we are transferring configured hadoop files from master to slave nodes
scp -r /opt/local/* [email protected]?:/opt/local scp -r /opt/local/* [email protected]?:/opt/local
Transfering environment configuration to slave machine
scp -r $HOME/.bashrc [email protected]?:$HOME/.bashrc scp -r $HOME/.bashrc [email protected]?:$HOME/.bashrc
Step 19 : Format namenode on hadoop master ( server1.bigdata.com )
Change the directory to /opt/local/hadoop/sbin $cd /opt/local/hadoop/sbin
Format the datanode.
$ hadoop namenode -format
hadoop namenode -format
WARNING: Use of this script to execute namenode is deprecated. WARNING: Attempting to execute replacement "hdfs namenode" instead.
2020-07-02 18:09:49,711 INFO namenode.NameNode: STARTUP_MSG: /************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = server1-cluster1/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.2.1
STARTUP_MSG: classpath = **********************************<Print all the classpath>**************
STARTUP_MSG: build = https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842; compiled by 'rohithsharmaks' on 2019-09-10T15:56Z
STARTUP_MSG: java = 1.8.0_252
************************************************************/
2020-07-02 18:09:49,729 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
2020-07-02 18:09:49,816 INFO namenode.NameNode: createNameNode [-format] 2020-07-02 18:09:50,236 INFO common.Util: Assuming 'file' scheme for path /app/hadoop/tmp/namenode in configuration.
2020-07-02 18:09:50,236 INFO common.Util: Assuming 'file' scheme for path /app/hadoop/tmp/namenode in configuration.
Formatting using clusterid: CID-1c02b838-66e7-4532-b57a-c0deddeaee1c
2020-07-02 18:09:50,268 INFO namenode.FSEditLog: Edit logging is async:true 2020-07-02 18:09:50,280 INFO namenode.FSNamesystem: KeyProvider: null
2020-07-02 18:09:50,281 INFO namenode.FSNamesystem: fsLock is fair: true
2020-07-02 18:09:50,282 INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false
2020-07-02 18:09:50,285 INFO namenode.FSNamesystem: fsOwner = hadoopuser (auth:SIMPLE)
2020-07-02 18:09:50,285 INFO namenode.FSNamesystem: supergroup = supergroup 2020-07-02 18:09:50,285 INFO namenode.FSNamesystem: isPermissionEnabled = false 2020-07-02 18:09:50,286 INFO namenode.FSNamesystem: HA Enabled: false
2020-07-02 18:09:50,313 INFO common.Util: dfs.datanode.fileio.profiling.sampling.percentage set to 0. Disabling file IO profiling 2020-07-02 18:09:50,329 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit: configured=1000, counted=60, effected=1000
2020-07-02 18:09:50,329 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=false
2020-07-02 18:09:50,332 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
2020-07-02 18:09:50,332 INFO blockmanagement.BlockManager: The block deletion will start around 2020 Jul 02 18:09:50
2020-07-02 18:09:50,333 INFO util.GSet: Computing capacity for map BlocksMap 2020-07-02 18:09:50,333 INFO util.GSet: VM type = 64-bit
2020-07-02 18:09:50,334 INFO util.GSet: 2.0% max memory 955.1 MB = 19.1 MB 2020-07-02 18:09:50,335 INFO util.GSet: capacity = 2^21 = 2097152 entries
2020-07-02 18:09:50,343 INFO blockmanagement.BlockManager: Storage policy satisfier is disabled
2020-07-02 18:09:50,344 INFO blockmanagement.BlockManager: dfs.block.access.token.enable = false
2020-07-02 18:09:50,348 INFO Configuration.deprecation: No unit for dfs.namenode.safemode.extension(30000) assuming MILLISECONDS
2020-07-02 18:09:50,348 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
2020-07-02 18:09:50,348 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.min.datanodes = 0
2020-07-02 18:09:50,349 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.extension = 30000
2020-07-02 18:09:50,349 INFO blockmanagement.BlockManager: 2
2020-07-02 18:09:50,349 INFO blockmanagement.BlockManager: 512
2020-07-02 18:09:50,349 INFO blockmanagement.BlockManager: 1
2020-07-02 18:09:50,349 INFO blockmanagement.BlockManager: =2
2020-07-02 18:09:50,350 INFO blockmanagement.BlockManager: redundancyRecheckInterval = 3000ms
2020-07-02 18:09:50,350 INFO blockmanagement.BlockManager: = false
defaultReplication = maxReplication = minReplication = maxReplicationStreams
encryptDataTransfer
2020-07-02 18:09:50,350 INFO blockmanagement.BlockManager:
= 1000
2020-07-02 18:09:50,382 INFO namenode.FSDirectory: GLOBAL serial map: bits=29 maxEntries=536870911
2020-07-02 18:09:50,382 INFO namenode.FSDirectory: USER serial map: bits=24 maxEntries=16777215
2020-07-02 18:09:50,383 INFO namenode.FSDirectory: GROUP serial map: bits=24 maxEntries=16777215
2020-07-02 18:09:50,383 INFO namenode.FSDirectory: XATTR serial map: bits=24 maxEntries=16777215
2020-07-02 18:09:50,401 INFO util.GSet: Computing capacity for map INodeMap 2020-07-02 18:09:50,401 INFO util.GSet: VM type = 64-bit
2020-07-02 18:09:50,401 INFO util.GSet: 1.0% max memory 955.1 MB = 9.6 MB 2020-07-02 18:09:50,401 INFO util.GSet: capacity = 2^20 = 1048576 entries 2020-07-02 18:09:50,402 INFO namenode.FSDirectory: ACLs enabled? false
2020-07-02 18:09:50,402 INFO namenode.FSDirectory: POSIX ACL inheritance enabled? true
2020-07-02 18:09:50,402 INFO namenode.FSDirectory: XAttrs enabled? true
2020-07-02 18:09:50,402 INFO namenode.NameNode: Caching file names occurring more than 10 times
2020-07-02 18:09:50,405 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: false, skipCaptureAccessTimeOnlyChange: false, snapshotDiffAllowSnapRootDescendant: true, maxSnapshotLimit: 65536
2020-07-02 18:09:50,408 INFO snapshot.SnapshotManager: SkipList is disabled 2020-07-02 18:09:50,410 INFO util.GSet: Computing capacity for map cachedBlocks 2020-07-02 18:09:50,411 INFO util.GSet: VM type = 64-bit
2020-07-02 18:09:50,411 INFO util.GSet: 0.25% max memory 955.1 MB = 2.4 MB 2020-07-02 18:09:50,411 INFO util.GSet: capacity = 2^18 = 262144 entries
2020-07-02 18:09:50,416 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
2020-07-02 18:09:50,416 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
2020-07-02 18:09:50,417 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
maxNumBlocksToLog
2020-07-02 18:09:50,421 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
2020-07-02 18:09:50,421 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
2020-07-02 18:09:50,423 INFO util.GSet: Computing capacity for map NameNodeRetryCache
2020-07-02 18:09:50,423 INFO util.GSet: VM type = 64-bit
2020-07-02 18:09:50,423 INFO util.GSet: 0.029999999329447746% max memory 955.1 MB = 293.4 KB
2020-07-02 18:09:50,423 INFO util.GSet: capacity = 2^15 = 32768 entries 2020-07-02 18:09:50,447 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1756667812-127.0.1.1-1593693590440
2020-07-02 18:09:50,462 INFO common.Storage: Storage directory /app/hadoop/tmp/namenode has been successfully formatted.
2020-07-02 18:09:50,498 INFO namenode.FSImageFormatProtobuf: Saving image file /app/hadoop/tmp/namenode/current/fsimage.ckpt_0000000000000000000 using no compression
2020-07-02 18:09:50,560 INFO namenode.FSImageFormatProtobuf: Image file /app/hadoop/tmp/namenode/current/fsimage.ckpt_0000000000000000000 of size 405 bytes saved in 0 seconds .
2020-07-02 18:09:50,568 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2020-07-02 18:09:50,573 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2020-07-02 18:09:50,573 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************
Step 20: Start Namenode, Secondary NameNode and DataNode daemon ( server1.bigdata.com )
$ start-dfs.sh
Step 21: Start yarn daemons. ( server1.bigdata.com )
$ start-yarn.sh
Step 22:
The JPS (Java Virtual Machine Process Status Tool) tool is limited to reporting information on JVMs for which it has the access permissions.
$ jps
10624 NodeManager 10128 DataNode 9986 NameNode
10986 Jps
10477 ResourceManager
Only on slave machines - (server2.bigdata.com and server3.bigdata.com ) $ jps
4849 DataNode
4979 SecondaryNameNode
5084 NodeManager 5310 Jps
$ jps
4277 NodeManager 4499 Jps
4145 DataNode
Congratulations! We have successfully completed the three-node installation setup for Hadoop 3.2.1. Please feel free to reach us through comments for any issues or queries.
We are a 360-degree SaaS app development company that specializes in providing end-to-end DevOps Services Provider to strengthen enterprise IT infrastructure. Our team of DevOps solutions and service providers have an extensive experience in using the latest tool and technologies to render technical infrastructure support with a focus on continuous delivery and continuous integration. We use agile development methodologies to streamline enterprise software architecture through our DevOps Services Provider . We also provide Cloud Application Development Services to prepare the project and formulate effective DevOps strategies to maximize enterprise benefits with end-to-end cloud integration.
#DevOpsSolution #SaaSaapDevelopment #DevOpsServiceProvider #CloudApplicationDevelopmentService
#DevOpsSolutionsandServices #DevOpsSolutionsandServiceProviders #DevOpsSolutions #CloudDevOpsConsultingServices #SaaSAppDevelopmentCompany


Cookies are important to the proper functioning of a site. To improve your experience, we use cookies to remember log-in details and provide secure log-in, collect statistics to optimize site functionality, and deliver content tailored to your interests. Click Agree and Proceed to accept cookies and go directly to the site or click on View Cookie Settings to see detailed descriptions of the types of cookies and choose whether to accept certain cookies while on the site.







About Author
Anirudh Bhardwaj
Anirudh is a Content Strategist and Marketing Specialist who possess strong analytical skills and problem solving capabilities to tackle complex project tasks. Having considerable experience in the technology industry, he produces and proofreads insightful content on next-gen technologies like AI, blockchain, ERP, big data, IoT, and immersive AR/VR technologies. In addition to formulating content strategies for successful project execution, he has got ample experience in handling WordPress/PHP-based projects (delivering from scratch with UI/UX design, content, SEO, and quality assurance). Anirudh is proficient at using popular website tools like GTmetrix, Pagespeed Insights, ahrefs, GA3/GA4, Google Search Console, ChatGPT, Jira, Trello, Postman (API testing), and many more. Talking about the professional experience, he has worked on a range of projects including Wethio Blockchain, BlocEdu, NowCast, IT Savanna, Canine Concepts UK, and more.