An overview on AWS Data Pipeline
Posted By : Yasir Zuberi | 31-Dec-2015
AWS Data Pipeline is a web service that transmits data. AWS Data Pipeline ensures managing and streamline workflow which is data-driven. AWS DP can be used for data manipulation and exposing data to data analysis tools.
AWS provides four ways to access Data Pipeline, you may use any of the following interface to create, access and manage your pipeline.
- AWS Management Console
- AWS Command Line Interface (AWS CLI)
- AWS SDKs
- Query API
Below is the list of Pipeline Objects
- Data Nodes
- Activities
- Resources
- Preconditions
- Databases
- Data Formats
- Actions
- Schedule
- Utilities
AWS allows you to create pipeline using console templates
For Example:- "Full Copy of RDS MySQL Table to S3" is a template which is used to copy an entire Amazon RDS MySQL table and stores output to an Amazon s3 location.
Note:- The output is stored as a CSV file under specified Amazon S3 location.
The template uses following pipeline objects
- CopyActivity which copies data from one location to another.
- Ec2Resource EC2 instance which performs work defined by pipeline activity.
- MySqlDataNode a data node using MySQL.
- S3DataNode a data node using Amazon S3.
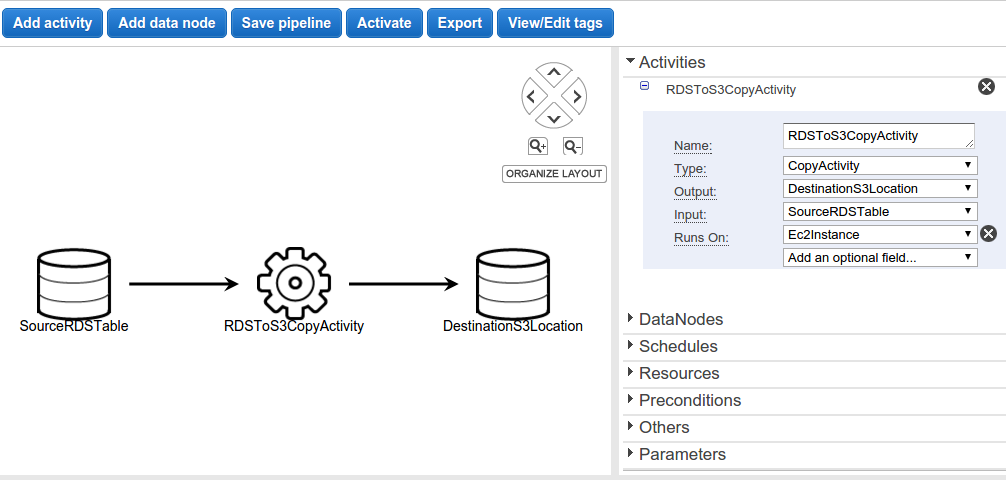
As you can see in above image it shows, two data nodes for input (SourceRDSTable), output (DestinationS3Location) and one copy activity(RDSToS3CopyActivity).
For more info on AWS PipeLine, you may refer to AWS Pipeline Documentation
Hope this helps.
Thanks


Cookies are important to the proper functioning of a site. To improve your experience, we use cookies to remember log-in details and provide secure log-in, collect statistics to optimize site functionality, and deliver content tailored to your interests. Click Agree and Proceed to accept cookies and go directly to the site or click on View Cookie Settings to see detailed descriptions of the types of cookies and choose whether to accept certain cookies while on the site.







About Author
Yasir Zuberi
Yasir is Lead Developer. He is a bright Java and Grails developer and have worked on development of various SaaS applications using Grails framework.